This report consists of two distinct research elements, with separate methodologies: a representative survey of U.S. adults conducted through Pew Research Center’s American Trends Panel and a content study of comments posted on the social forum reddit.com.
Reddit, whose slogan proclaims it to be the “front page of the Internet,” is part social network, part online forum (read here for more on how Reddit works). It features a broad mix of topics dispersed across a complex but structured environment. Moreover, its reach extends beyond the confines of the site itself, from driving traffic to external sites to attracting attention from political figures, including President Obama.
Survey
American Trends Panel January 2016 wave
The American Trends Panel (ATP), created by Pew Research Center, is a nationally representative panel of randomly selected U.S. adults living in households. Respondents who self-identify as internet users and provided an email address participate in the panel via monthly self-administered Web surveys, while those who do not use the internet or decline to provide an email address participate via the mail. The panel is being managed by Abt SRBI.
Data in this report pertaining to the Reddit usage and news usage numbers are drawn from the January wave of the panel, conducted Jan. 12-Feb. 8, 2016, among 4,654 respondents (4,339 by Web and 315 by mail). Panelists who have access to the internet but take surveys by mail were not sampled in this wave (i.e. mail respondents to this wave are all non-Internet users). The margin of sampling error for the full sample of 4,654 respondents is plus or minus 2 percentage points.
Members of the American Trends Panel were recruited from two large, national landline and cellphone random digit dial (RDD) surveys conducted in English and Spanish. At the end of each survey, respondents were invited to join the panel. The first group of panelists was recruited from the 2014 Political Polarization and Typology Survey, conducted Jan. to March 16, 2014. Of the 10,013 adults interviewed, 9,809 were invited to take part in the panel and a total of 5,338 agreed to participate.8 The second group of panelists was recruited from the 2015 Survey on Government, conducted Aug. 27 to Oct. 4, 2015. Of the 6,004 adults interviewed, all were invited to join the panel, and 2,976 agreed to participate.9
Participating panelists provided either a mailing address or an email address to which a welcome packet, a monetary incentive and future survey invitations could be sent. Panelists also receive a small monetary incentive after participating in each wave of the survey. This new edition of our February 2016 report contains updated survey data. It takes into account newer weighting measures that the Pew Research Center has adopted for its American Trends Panel.
Under the revised protocol, the ATP data are weighted in a multi-step process that begins with a base weight incorporating the respondents’ original survey selection probability and the fact that in 2014 some panelists were subsampled for invitation to the panel. An adjustment was made for the fact that the propensity to join the panel and remain an active panelist varied across different groups in the sample. The final step in the weighting uses an iterative technique that matches gender, age, education, race, Hispanic origin and region to parameters from the U.S. Census Bureau’s 2014 American Community Survey. Population density is weighted to match the 2010 U.S. Decennial Census. Telephone service is weighted to estimates of telephone coverage for 2016 that were projected from the January-June 2015 National Health Interview Survey. Volunteerism is weighted to match the 2013 Current Population Survey Volunteer Supplement. It also adjusts for party affiliation using an average of the three most recent Pew Research Center general public telephone surveys. Internet access is adjusted using a measure from the 2015 Survey on Government. Frequency of internet use is weighted to an estimate of daily internet use projected to 2016 from the 2013 Current Population Survey Computer and Internet Use Supplement. The share of respondents who get news from 10 different social networks was weighted to match a Pew Research Center Journalism survey from March-April, 2016.
The following table shows the unweighted sample sizes and the error attributable to sampling that would be expected at the 95% level of confidence for different groups in the survey:
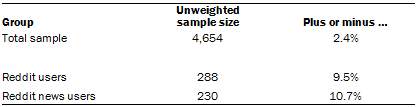
Sample sizes and sampling errors for other subgroups are available upon request.
In addition to sampling error, one should bear in mind that question wording and practical difficulties in conducting surveys can introduce error or bias into the findings of opinion polls.
The Web component of the January wave had a response rate of 69% (4,339 responses among 6,301 Web-based individuals in the panel); the mail component had a response rate of 67% (315 responses among 474 non-Web individuals in the panel). Taking account of the combined, weighted response rate for the recruitment surveys (10.0%) and attrition from panel members who were removed at their request or for inactivity, the cumulative response rate for the January ATP wave is 2.9%.10
American Trends Panel January 2016 early respondents
Data in this report that pertains to learning about the 2016 presidential election from Reddit are drawn from the early respondents to the January 2016 wave of the panel. These 3,760 respondents consisted of 3,661 Web panelists who had completed the survey by January 27 and 99 mail panelists whose responses had been received by January 22. The margin of sampling error for these 3,760 respondents is plus or minus 2.3 percentage points. The weighting procedure for this early responder part of the January 2016 wave was the same as the full sample as discussed above.
The following table shows the unweighted sample sizes and the error attributable to sampling that would be expected at the 95% level of confidence for different groups in the survey:

Sample sizes and sampling errors for other subgroups are available upon request.
In addition to sampling error, one should bear in mind that question wording and practical difficulties in conducting surveys can introduce error or bias into the findings of opinion polls.
The Web component of the early responders of the January 2016 wave had a response rate of 58.1% (3,661 responses among 6,301 Web-based individuals in the panel); the mail component had a response rate of 20.9% (99 responses among 474 non-Internet users in the panel). Taking account of the combined, weighted response rate for the recruitment surveys (10.0%) and attrition from panel members who were removed at their request or for inactivity, the cumulative response rate for the early respondents to the January 2016 ATP wave is 2.5%.
Content analysis
To gain a sense of how presidential candidates have been discussed within Reddit, researchers gathered publicly available comments and analyzed them using a mix of machine learning techniques and human content analysis.
Researchers examined comments that included the names of U.S. presidential candidates during the months of May, June and September 2015. Center researchers initially downloaded the two most recent months available – May and June – and then later, when made available, added September, when the campaign was getting into full swing and the candidates were engaging in the first debates.
Data Acquisition
For this project, researchers pulled mentions of every major political candidate during May, June and September 2015 from a dataset of all Reddit comments published by Jason Baumgartner (http://pushshift.io) to reddit.com, archive.org and Google BigQuery in June 2015 and updated monthly since then. This dataset was constructed by requesting comments in large, concurrent batches from the Reddit application program interface (API). Researchers conducted tests on a subset of the data (comments from the month of June) to ensure that relevant comments were not missing from the dataset overall. With the exception of those that had been deleted before Baumgartner’s software requested them, no comments were found to be missing from the data.
Researchers took several steps to identify and study a total of 21 presidential candidates. To explore the conversation about those candidates, researchers developed and refined SQL queries on the Google BigQuery dataset described above to identify relevant comments for each one. This iterative process was used to return as many comments that were about a candidate as possible without returning large swaths of comments that were clearly not related to the candidate.
Accordingly, researchers began with a candidate’s first and/or last name. All searches for candidates included both their first and last name as a string (e.g. “Ben Carson”) as well as their last name (“Carson”), with the exception of Rand Paul, for whom the candidate’s full name was used, as “Paul” would have captured too many off-topic comments. Depending on the prominence of the candidate’s first name in discussions about him or her, researchers also included it as an independent search term. For instance, Jeb Bush is often referred to just as Jeb, especially in informal discussions; whereas Scott Walker is infrequently referred to as just Scott – and if he was, it would be difficult to distinguish between discussions of the Wisconsin governor and others sharing his first name. Researchers then constructed SQL queries with regular expression search terms to account for possessive permutations of the name, variances in spacing and punctuation, and other characteristics of Web discussions.
Once the initial queries were constructed, researchers tested them for accuracy by combing the results for frequent off-topic discussions. Because researchers were using names as the search terms, famous individuals with similar names were often captured by the search results. For example, Rick Perry’s search results included discussions of actor Matthew Perry, singer Katy Perry, and filmmaker and actor Tyler Perry. We systematically excluded those names from the search results. The point of this exercise was not to narrow down the search results only to those that were about the candidate – we recognized early on that SQL was not well suited to this task – but to ensure that the result set was pruned of the most prominent false positives, which would lower the amount of off-topic comments in subsequent steps.
To be sure, there are natural limitations to this approach. For instance, comments may discuss candidates without naming them – opting instead to use pronouns such as “him” or her.” It is also important to note that this analysis is conducted on the comments that appear under submissions, not the submissions themselves. This decision was made in part because comments appear more frequently than do individual posts, and because they represent the closest thing to a proxy for participant conversation on the site. In addition, the initial data set made available to researchers was at the comment level. (While researchers did some exploratory analysis of submission data gathered directly from the Reddit API, analyzing the submissions would have made for a distinct and separate project altogether.) Despite these limitations, the data collected and studied here represent the essence of how conversation functions on this news-heavy platform.
Coding
The resulting dataset consisted of over 2.2 million comments, a number large enough to render manual content analysis impractical. Instead, this project utilized manual analysis to train a machine learning model to determine which comments were discussing presidential candidates.
A team of coders first evaluated each comment that was identified from the database using a binary classification scheme – either the comment was about the specific presidential candidate or it was not. In each of the three months, for all 21 candidates, if the name search returned less than 500 results, researchers coded all results. If it returned more than 500, researchers coded at least 500 but up to 3,000+ in order to achieve reliability on the classifier. Overall, researchers hand-coded more than 50,000 comments. Four coders coded May and June data after reaching a Cohen’s Kappa of .86. A separate group of three coders coded September data. Coders reached a Cohen’s Kappa of .87, within the acceptable range of reliability.
Researchers then employed Support Vector Machines (SVMs), which are a frequently used class of machine learning models. When used in text analysis, they classify data by analyzing the language used across the entire document (in this case, each “document” consists of a single comment on Reddit). SVMs receive input in the form of training and test data, which is a set of documents that have been coded manually by trained researchers. Analyzing the training data, the algorithm identifies patterns in the language used for all documents associated with each code and develops a set of rules to classify subsequent documents. It is evaluated using a set of labeled documents not used in training.
Researchers tuned the SVMs such that they were able to predict new documents with a score of .80 or higher.
After the SVMs constrained the dataset to just those comments that were about presidential candidates, researchers further inspected the non-news or politically relevant subreddits with high numbers of comments in which a candidate was identified. Researchers randomly inspected 50 comments from these subreddits, and if the vast majority of them were not about the candidate in question, that subreddit was excluded from analysis. This occurred most frequently in the Entertainment category.
The final dataset included more than 350,000 comments.
Subreddit Coding
Much of the analysis in this report was conducted on comments within broad subreddit categories, rather than individual comments or submissions. To determine the categories, manual content analysis was employed. A team of three coders with expertise in social media developed a codebook with 14 subreddit categories. After training on this codebook, these coders coded a sample of 48 subreddits by inspecting the subreddit description or wiki (where available) and frontpage posts and comments. This process achieved a Cohen’s Kappa of .82.
All subreddits with at least 50 comments were coded by a member of this team, resulting in 409 subreddits. Using the method described above, 36 of these subreddits were removed because their comments were misidentified by the SVM. Subreddits were categorized accordingly:
- Web culture: 63
- Entertainment & sports: 55
- Issue-specific: 35
- Geographic (within U.S.): 32
- Candidate-specific: 28
- General information exchange: 24
- General politics: 24
- Geographic (outside U.S.): 19
- Ideology-specific: 18
- Identity-centric: 13
- General news: 12
- Religion: 11
- Party-specific: 3
- Other: 36
© Pew Research Center, 2016






