A new Pew Research Center analysis of the conversation on Twitter leading up to the European Parliament elections suggests mixed sentiment toward the European Union (EU) and a general lack of passion about the candidates seeking the European Commission presidency.
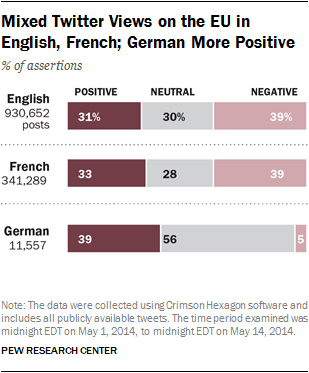
In the analysis of more than 1.2 million tweets in English, French and German collected between May 1-14, a decidedly mixed view about the EU emerged. In English, 31% of the assertions on Twitter about the EU were positive toward the EU (which included the EU directly, its institutions and Europe), compared with 39% that were negative and 30% that were neutral. The Twitter conversation in French broke down the same basic way—33% positive, 39% negative and 28% neutral. And while the German language conversation about the EU on Twitter was much more positive (39%) than negative (5%), these views were embedded in a low intensity conversation that represented a mere fraction of the Twitter activity in French and English.
The positive view toward the EU was reflected in a tweet from Finnish minister Alexander Stubb who wrote: “We need the EU for four simple reasons: peace, prosperity, security and stability. We can do more together, than alone.” The opposite view was voiced in a tweet from @MetManPH noting that, “It’s not racist to believe that membership of the EU is not in Britain’s best interests.”
Other elements of the Twitter discussion in the run-up to the May 22-25 balloting for a 751-seat pan-European Parliament reinforce the notion that the 28-nation organization does not provoke particularly strong interest or approval in this corner of the social networking world.
The pan-European elections are organized and governed by each country’s national parties which put forward candidates for the European Parliament.
While a rather robust Twitter conversation emerged around the national parties in each of the three languages, the party for that country that generated the most attention was one with either a distinctly anti-EU platform or a party critical of the common currency, the Euro.
Additional analysis of the English-language discussion about each of the five candidates for the European Commission presidency demonstrated the degree to which the parties draw more attention than individual candidates. None of the candidates received more than 12,886 English-language tweets in the time studied. Even considering that some candidates may have gotten additional attention in their native languages, these numbers are quite small. (British Prime Minister David Cameron received 133,390 tweets alone during the same period.) The tone of Twitter sentiment toward each of those presidential candidates was overwhelmingly neutral—with between 65% and 79% of the tweets not being either markedly positive or markedly negative.
As a 2013 Pew Research Center report noted, Twitter opinion about major issues and events frequently differs from broad public opinion, since those using the social media site often comprise a small slice, rather than a representative sample, of the general public. A recent Pew Research Center survey providing representative opinion in seven EU nations found that citizens’ views of the EU in France and the U.K. are somewhat more favorable than what is reflected in the Twitter conversation.1
In the U.K., 52% of the survey respondents had a favorable view compared to 41% unfavorable; in France it was 54% favorable, 46% unfavorable. The more favorable tone of the German response on Twitter, however, was generally in sync with overall German public opinion as measured in the Pew Research poll, which was considerably more favorable (66%) than unfavorable (31%) about the EU. On other measures, such as whether the EU listens to and understands the needs of Europeans, national public opinion seems more in tune with the general lack of enthusiasm on Twitter.
This report on the Twitter conversation related to the EU elections tracked all those tweets in each of the three languages from May 1 through May 14. This covered the period between the April 28 and May 15 debatesbetween the Commission presidential candidates. Pew Research used computer coding software provided by Crimson Hexagon and the Twitter sample for this study is derived from “the Twitter Firehose data feed,” which includes all public tweets from the Twitter system. The analysis examined those tweets that directly addressed the European elections and the European Union.2
Pew Research chose to analyze tweets by language (English, French and German) and to not limit the content to specific countries. While Twitter has several methods to identify the location where a tweet originated—also known as geo-tagging—only a small percentage of tweets are accurately tagged and Pew Research concluded that the geo-tagging data was not thorough enough to use as part of this project. Because geo-tagging is not precise, some tweets in a given language may not originate from the country most associated with that language. Some tweets in German, for example, originate from Austria, while some tweets in French may come from Belgium or Luxembourg.
Our analysis and data on social media also show that Twitter usage is light in Germany compared with some other countries. While Twitter has publically released figures citing 15 million monthly active users in the U.K., it has not released figures for usage in France or Germany. A number of different metrics produced by a mix of European firms and think tanks indicate that among those three countries, Germans use social media the least and the English use it the most. (See the 2013 Eurobarometer study or data published by the eMarketer) In addition, a 2012 Pew Research survey found that 52% of the British used social networking sites, compared with 39% of the French and 34% of Germans. For every aspect of the Twitter conversation studied, there were considerably fewer German-language tweets than tweets in English and French.
That was very obvious in the volume of tweets registering sentiment toward the EU. There were nearly a million (930,652) Twitter posts in English, and about one-third as many in French. By those standards, the German discussion was virtually non-existent, consisting of only 11,557 tweets.
The EU Commission presidential candidates represent pan-European parties (or Europarties) that are aligned with each country’s national parties. And since these national parties actually conduct the campaigns, they attracted considerable interest on Twitter.
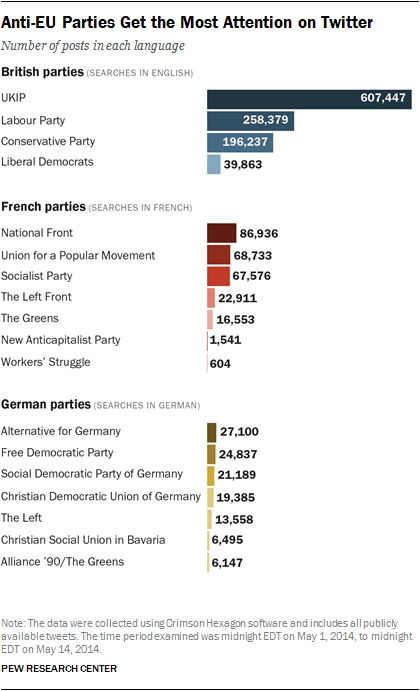
In examining the social media discussion related to those national parties in the U.K., France and Germany, one common element emerged. In each case, a national party with an explicitly anti-EU or anti-Euro platform generated the most attention.
In the U.K., that was the right-wing U.K. Independence Party, or UKIP, which favors the country leaving the EU. From May 1-14, Twitter users produced 607,447 tweets about UKIP, which is more than for the Tories, the Labour Party and the Liberal Democrats combined.
In France, the far-right National Front is a vocally anti-EU party. And while the volume of the Twitter conversation was smaller in French than in English, the National Front (almost 86,936 tweets) received more attention than any other national party. The center-right Union for a Popular Movement was next, at nearly 68,733.
Once again, the Twitter activity in German was considerably less than in English and French. But the same pattern held. The party that generated the most tweets (about 27,100) was the Alternative for Germany, which has campaigned against the common European currency, the Euro. The center-right Free Democratic Party was not far behind, with about 24,837.
Pew Research did not examine the national party tweets for sentiment, so it’s not known how many of these Twitter opinions about the anti-EU parties were positive or negative. But it is clear that they attracted the most attention in social media.
Compared to the social media conversation about the national parties, there was a sparse English-language Twitter conversation about the five candidates vying for the European Commission presidency: Jean-Claude Juncker of Luxembourg, from the center-right European People’s Party; Martin Schulz, of Germany, from the center-left Party of European Socialists; Guy Verhofstadt, of Belgium, representing the Alliance of Liberals and Democrats for Europe; Alexis Tsipras, of Greece, from the European Left Party; and Ska Keller, of Germany, from the European Green Party.
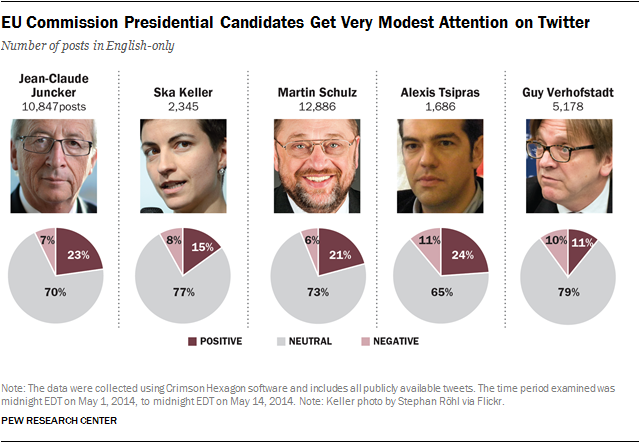
These candidates are from different national backgrounds and thus may have had received additional Twitter attention in their own language. But English is one of the three core EU languages, the main language used in the two televised candidate debates and the one with the largest presence in the Twitter conversation. This analysis does not capture all the conversation about the candidates, but it offers insights into how this segment of Twitter users talked about them and to one of the challenges candidates face in the EU structure. The two candidates with the highest volume, Juncker and Schulz, have a strong European profile. Juncker was the head of the Eurogroup, a group consisting of all the Eurozone’s finance ministers and Schulz has been the President of the European parliament since 2012. Tsipras, the head of the opposition party in Greece, is more of a national than pan-European figure.
In contrast, Pew Research identified 133,390 tweets about British Prime Minister David Cameron in the same May 1-May 14 period.
With the exception of Verhofstadt—whose verdict was mixed—the tone of the Twitter discussion about each of the candidates was more positive than negative. But what is more striking is the large percentage of assertions that did not carry a clear opinion about the virtues or liabilities of the candidates. The percentage of neutral assertions about the contenders ranged from a low of 65% for Tsipras to a high of 79% for Verhofstadt.





